从GITHUB ACTION起搭建简易CI/CD系统
自动化部署的原因与结构
当我们刚开始建立项目或者规模比较小的时候,一般直接在内网部署简单的环境自我测试。
但是无论是自己使用还是面向大众,最后我们都需要将项目上线。上线后,我们应当尽可能的自动化部署以节省时间。
自动化部署的流程分为几个部分:
- 当代码提交或者满足我们的一定条件后自动触发此流程
- 打包机:下载改动到本地
- 打包机:前端打包、后端编译
- 打包机:推包到正式环境
- 正式环境:关闭服务
- 正式环境:使用新包重启环境
本文将针对我在这个流程中发现的坑和最终用部署的流程分几个部分进行探索。
因为我目前的项目,生产环境比较小,所以打包机和生产环境放在一台机子上,本文的内容也建立在此基础编写。用户领会精神就行。
自动触发更新-GITHUB ACTION
我使用GITHUB做项目的版本管理,所以采用GITHUB ACTION来自动化更新流程。GITHUB ACTION支持根据事件触发对应的程序。这个程序的功能是相当完备的,可以选择镜像建立容器,在容器中执行诸多操作。例如通过SSH登录,然后触发服务器的打包重启。这个流程中可以调用很多官方或者第三方的集成操作例如github secret或者ssh。
如何创建工作流
在项目根目录创建文件夹 .github/workflows。
在其下创建 yml 文件,例如 deploy.yml
内容可以参考如下:
name: 自动部署
on:
push:
branches:
- master
jobs:
deploy:
runs-on: ubuntu-latest
steps:
- name: SSH登录
uses: webfactory/ssh-agent@v0.5.3
with:
ssh-private-key: ${{ secrets.SSH_KEY }}
- name: 执行更新脚本
run: |
ssh -o StrictHostKeyChecking=no ${{ secrets.SSH_USER }}@${{ secrets.SSH_HOST }} 'source ~/.zshrc && zsh 更新脚本'
请注意下提交yml本身也会触发更新逻辑,不要把不成熟的脚本向正式环境放。
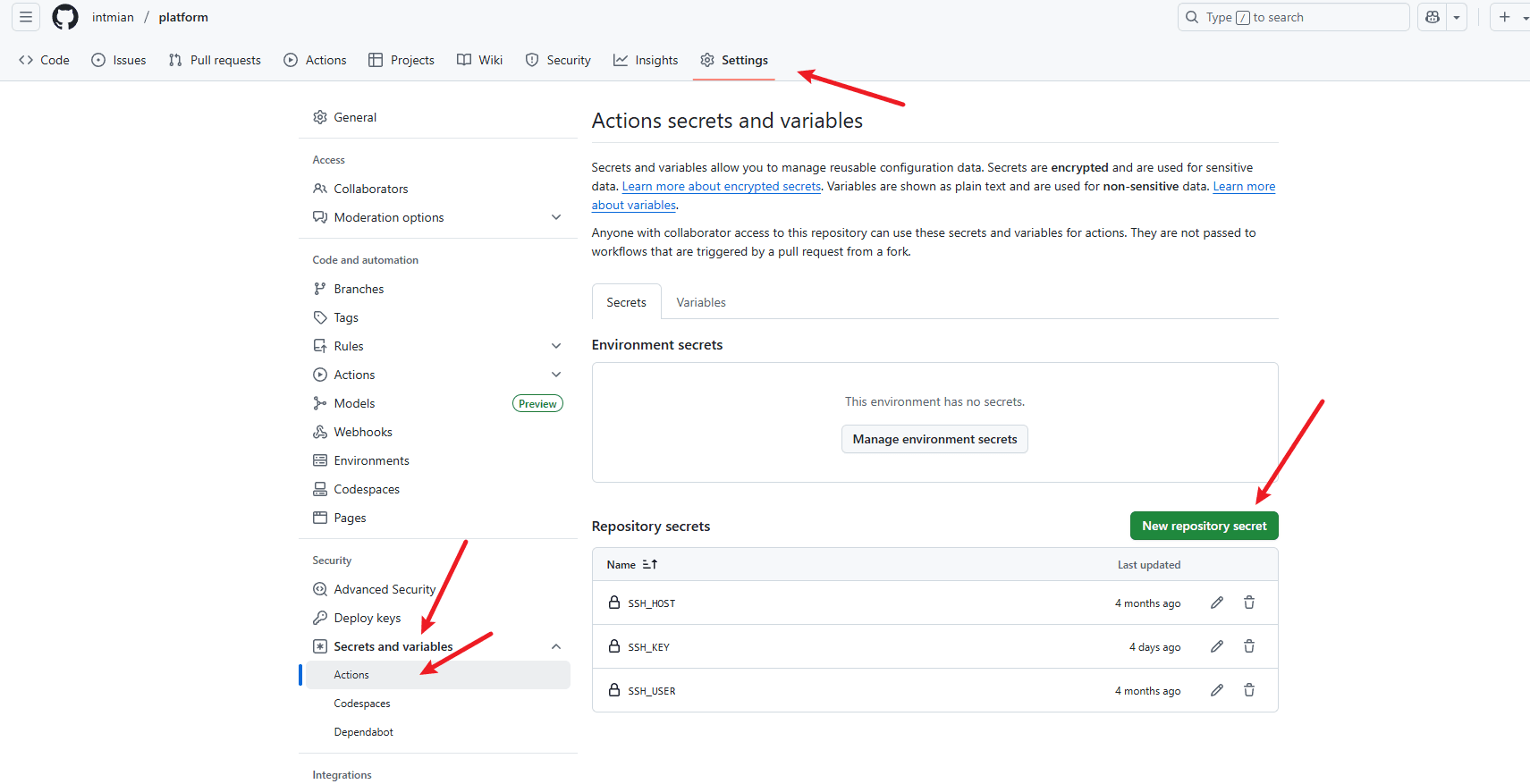
secret
${{ secrets.SSH_KEY }}类似的符号是在github项目中部署的,需要特别注意SSH_KEY需要复制登录时ssh的全部。
更新脚本替换成自己的脚本就行,如果使用zsh前面的不用改,如果使用bash对应修改下就行。但是需要注意常用的脚本和环境变量问题。
私钥不要直接写在action,这是很不安全的。secret调用时在action显示的时候会打码,敏感路径也是如此,比如root。
zsh|go
因为go不是将程序放在bin文件夹而是我们自行将对应文件夹加到.zsh文件中,所以需要指定go程序或者直接调用source ~/.zshrc 。只有交互式的ssh才会自动调用source ~/.zshrc 。直接使用ssh调用指令是不交互的,不会调用这个。所以需要在脚本中调用。
master|main
如果不触发的话,需要留意下分支是否正确。默认的分支可能是main或者master,需要注意下。
同时多人提交
如果在上一个action没有执行完成的情况下提交了新的提交,后一条提交不会触发更新。如果有多人协作的情况,需要单独维护一个发布用分支。
本地更新脚本
编译、打包、重启脚本根据业务自己写就行,但是需要以下问题:
jwt加盐有效期
jwt一般需要初始化加盐需要的几个随机变量,如果每一次重启都刷新,会导致用户需要频繁重新登录,在敏捷开发中可能较为不利,但是不初始化会有安全问题。可以将重启日期(月、日)和自定义盐hash后的值用来真正加盐。
在某一些登录后会续签的系统中,因为用户习惯一直处于登录,这一点更为重要。
编译以及打包问题
在构建和部署流程中,如果使用的是依赖较少、第三方库较少的技术栈,可以直接在 GitHub Actions 等 CI 环境中完成编译和打包工作。然而,对于像 Node.js 这类依赖庞大、体积较大的项目,直接在 CI 环境中打包往往会显著拉长构建时间,影响整体部署效率(因为拉起依赖和没有打包、编译的缓存)
为节省时间,建议将打包工作放在打包机中完成,然后 触发部署脚本,这样既能提升构建效率,也便于维护。尤其在 GitHub Actions 中,如果脚本逻辑过于复杂,不仅难以维护,还容易造成流程混乱。
另一种可选方案是:在本地完成打包并直接上传构建产物。这种方式的优点是可控性高,避免了 CI 环境下冗长的构建流程。但缺点也显而易见——每次发布前都需要手动操作上传过程,流程繁琐,而非只需提交更新即可。此外,对于需要编译为二进制的后端项目,还可能遇到诸如交叉编译等兼容性问题。
综上所述,打包策略应结合项目依赖规模、构建复杂度与团队工作流实际情况进行合理选择。需要注意的一些问题
一些改进,最好需要推送因为成功没有提示以及关闭的报告
出于安全考虑,在自动化执行时可以考虑在关闭和开启时在运维平台进行推送,golang可以这样写:
// 做下退出的警报
sigC := make(chan os.Signal)
signal.Notify(sigC, os.Interrupt, syscall.SIGINT, syscall.SIGTERM)
go func() {
sig := <-sigC
p.log.Info("PLAT", "receive signal %v, exit", sig)
err := p.push.Push("PLAT", "因外部信号,服务器已退出", false)
if err != nil {
p.log.WarningErr("PLAT", errors.WithMessage(err, "push exit err"))
}
time.Sleep(time.Second)
os.Exit(0)
}()
更新脚本时序问题
停止程序时,常常需要处理一些逻辑,例如释放资源或者发送通知,往往不是立刻执行的,所以不能kill后立刻启动,需要等待程序结束。脚本可以这样写
# 查找并停止旧的后台进程(通过进程名 'platform_back' 来识别)
pid=$(pgrep -f "$base_addr/pack/platform_back")
if [ -n "$pid" ]; then
echo "正在停止旧的后台进程,PID: $pid"
kill "$pid"
# 等待进程退出的循环逻辑
for i in {1..10}; do # 最多等待100秒
if ps -p "$pid" > /dev/null; then
echo "等待进程退出中..."
sleep 2
else
echo "旧的后台进程已成功停止"
break
fi
done
# 如果超时还未退出,强制终止
if ps -p "$pid" > /dev/null; then
echo "进程未在规定时间内退出,强制终止"
kill -9 "$pid"
echo "旧的后台进程已被强制终止"
fi
else
echo "未找到旧的后台进程"
fi
screen、nohup、systemed对比
在 Linux 生产环境中,nohup、screen 和 systemd 都可用于确保进程在终端关闭后继续运行。nohup 适合快速将程序放到后台运行,操作简单但功能有限;screen 则提供可恢复的交互式会话,适合需要监控或长期交互的任务;而 systemd 是现代 Linux 的服务管理框架,更加稳定可靠,适用于以服务形式长期运行的程序,支持自动重启、日志管理和开机自启等功能,是生产环境中管理守护进程的首选。根据实际需求选择合适工具,有助于提高系统的可维护性与稳定性。
因为screen需要安装,而且自动化执行有一些小问题(可能是我不会用),systemed用起来有点点麻烦,所以我最后偷懒使用的nohup。
nohup "$base_addr/pack/platform_back" > "$log_file" 2>&1 &
后言与近况
这篇博客其实成文于年初,因为太忙了搁置忘了。最近空下来了,打算写博客,才发现有一篇博客只有大纲,决定把坑填了。
过年左右,我一直在进行platform的todone任务模块的开发。本来打算在年前开发完,但是大大低估了工作量。节后,因为很多原因,我们公司突然开启了99工作制,繁琐的工作很多,非常的繁忙。
所以一直到五一假期的第三天才基本上完成开发,之后又因为工作上很忙,加上一些开发经验不足,导致有些部分重构了好几次。一直到上周版本才算是稳定了下来。
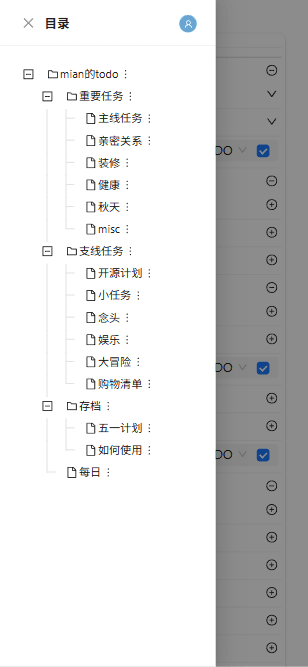
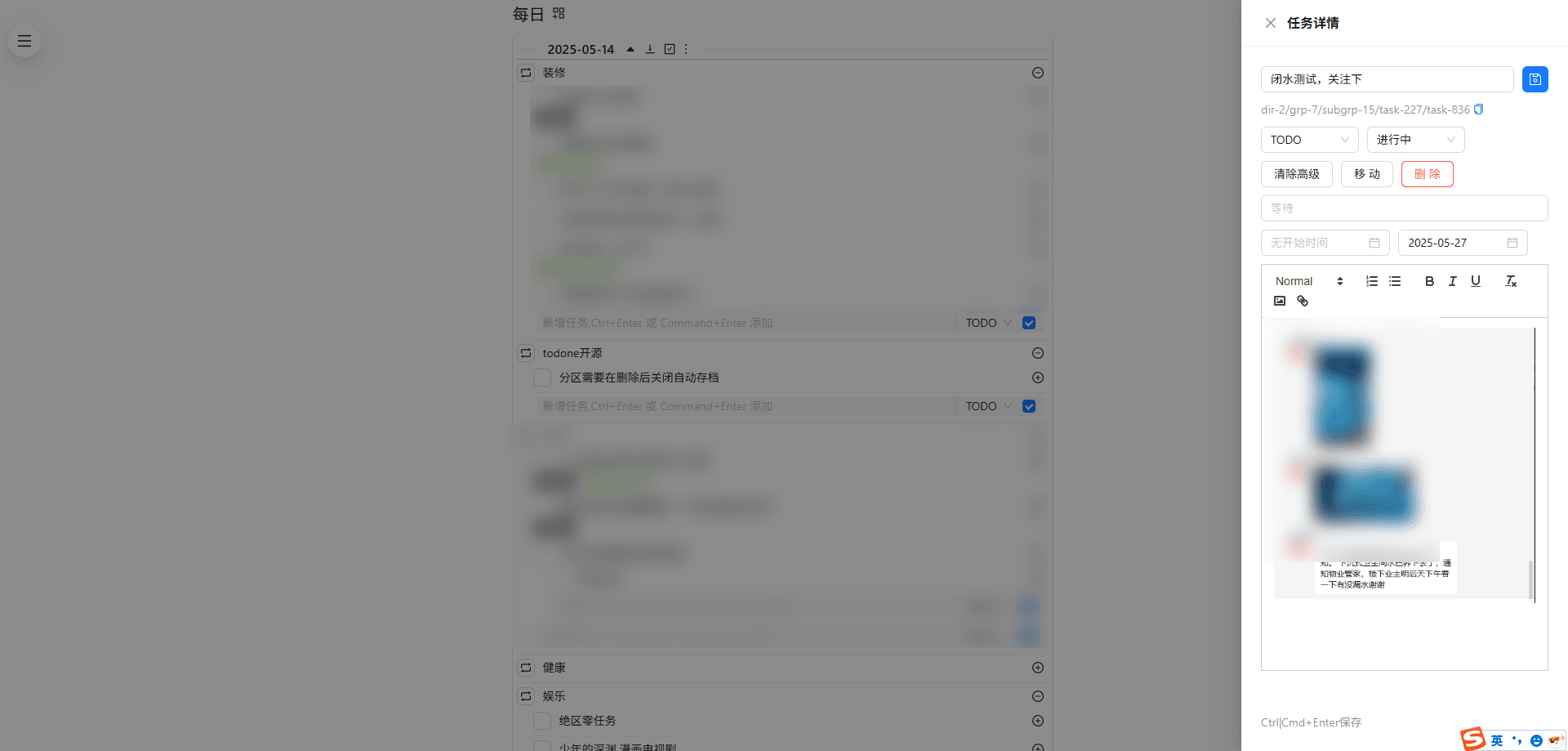
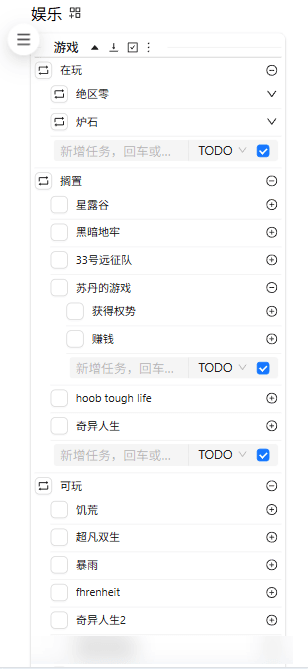
这周的业余时间我把老的任务系统全部迁移进了新的todone系统中。回头看,感觉还蛮有成就感的,开发一个自部署的类似于游戏中的任务系统的轻量任务面板一直是我的夙愿。当然也是plat一期开发计划的重要一环。这是我之前想做但是做不到的事情,随着自己的提升也做到了!
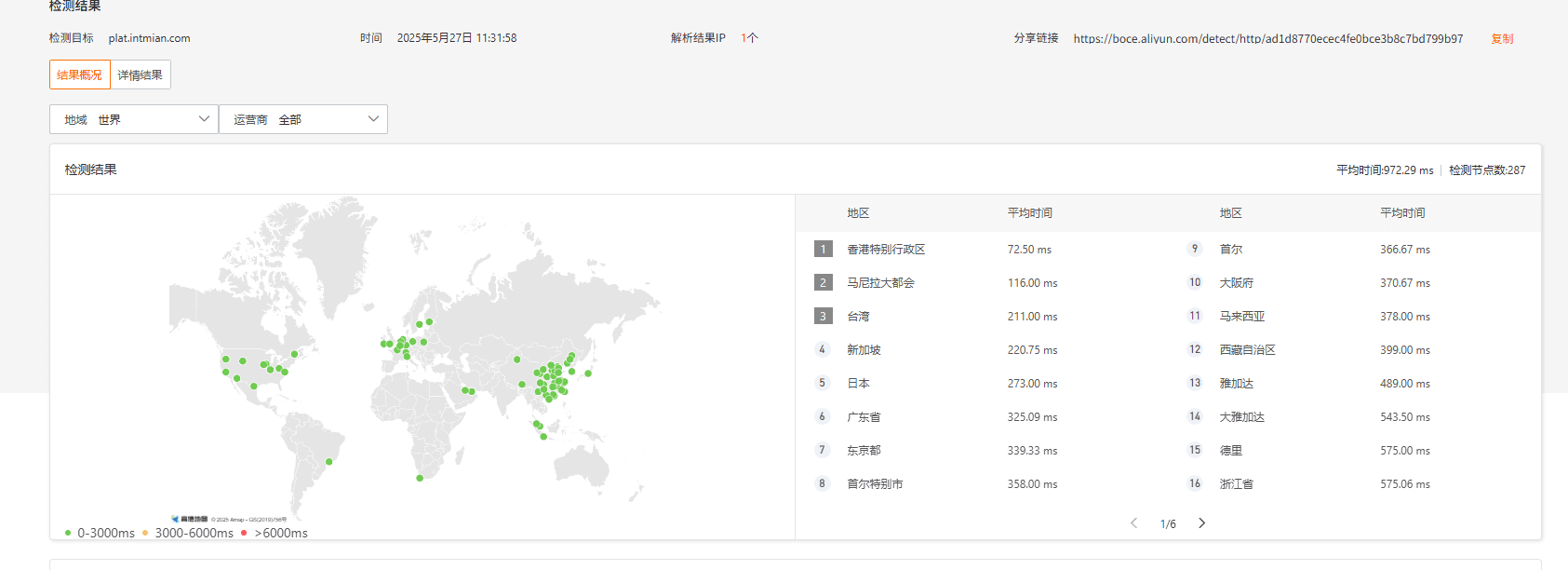
另外,上周还顺手把服务器从华为云迁到了阿里云。老实说,从那卡得我连 SSH 都进不去的日子解脱出来,真的像换了个人生。现在连访问后台都觉得丝滑多了,服务器终于“正常发挥”了。朋友们也再也不会感觉我的网页卡卡的了。之前用华为云网络很差,加上Cloudflare D1通过HTTP接口访问数据库延迟极高(查询0.xms,响应却超过1000ms),导致todone反应慢得几乎没法用。换到阿里云后,网络顺畅多了,再加上加了有状态缓存,todone终于变得灵敏起来,虽然我辛苦做的loading特效几乎用不上了,但成就感还是挺足的。
顺便炫耀下1.0阶段的todone,不仅做了手机端的适配,顺便把我在使用苹果提醒事项时觉得有xxx、yyy就好了,中的这些“xxx、yyy”都是实现了,也算是真正的面向自己的定制开发,完全契合了自己的需求。
platform是支持多用户的,如果有一天我完成了platform的开发,并打磨好了,加上现在服务器的高全球可用性,也许可以供大家一起用吧,而不仅是自嗨产品。
希望有那一天吧:)
p1 引以为傲的网络
p2-4 todone展示界面