从1开始了解git
前言
我并不是很会git。虽然大学时写了很多代码,但多半是小打小闹,也缺乏多人协作的经历。工作后一直工作在一家主要使用svn的公司。虽然在github上零零碎碎交过一些pr,也曾经在github接受过一些别人的pr,但是都是按部就班的根据教程来,哪里不会点哪里,没有系统的研究过。
最近需要和一些朋友合作开发一些开源库和闭源项目。作为主导者,没有别人的教导,反倒是我需要为项目制定规章。因此细细研究了一遍git文档。
研究后发现很多我觉得很hack的方法,本质上就是一些很简单的逻辑组合而成。所谓“太过强大的黑盒与魔法无异”。今天我在这儿梳理下我的理解,个中错误望各位读者海涵。本文仅供个人复盘与落实费曼学习法,默认读者具备基础git知识与操作经验。
基础、用户与提交之前的暂存
git内架构
git管理的项目由.git文件夹和其他文件组成。除了.git文件夹外的部分就是我们管理的项目文件。.git文件夹由两部分组成:快照和暂存区。
暂存区是我们希望记录更改的那些文件。因为设计者希望用户一个提交可以改动多个文件,所以当我们对一个修改后的文件执行git add *指令后,改动会以快照的形式放在暂存区。
我们的改动将会以一颗快照树的形式被存储进提交树。快照树包含改动了哪些文件和具体每个文件的改动。文件的改动包含改变后文件状态和改变的内容。假如我们在a版本号进行了b提交,那么在提交树中,b提交会被作为子节点缀在a上。一个提交可能有一个父节点(普通提交),也可能有两个(合并)。需要注意,提交树并非是不可篡改的。本地的提交历史可能会被rebase篡改,而远程仓库则会被force push修改。
提交者
当我们提交时,提交会标识提交者。提交者的身份信息由git配置决定的。我们可以决定我是谁。因此,提交历史本身可能是不可信的,我可以伪装成linus给linux项目提交代码以绕过一些检查。如果合并者没有细心检查,那我就可以把系统崩溃的责任推给linus。我们可以使用一些密码学方法使我们提交是经过校验的(时间与作者是可信的)。通常,开源项目要求提交必须是经过校验的。
新建项目
创建一个git管理的项目,首先必须从某一个文件夹开始。当我们准备好这个文件夹,cd 进项目的内部执行git init,此时git项目是空的。
更新项目
默认情况下git会追踪所有的文件。出于性能和操作便捷的影响,我们会在.gitignore里面标注哪些文件是需要忽视的。
在我们对项目文件做出一些改动后,如果我们希望记录一部分或者全部的改动,我们可以用多个git add file或者git add *的形式将这些改动的文件,他们的改动添加到暂存区。然后我们执行git commit将改动提交到本地提交历史。我们只能在提交树的头部进行提交。后文我会介绍一些方法对提交树本身进行操作。
提交、分支与分支操作
前文讲到多个提交会以树的形式串联。之所以说是树而非链就是因为提交历史并非是不可分叉的。如果我们有需要,例如我们希望同步更改多个功能、希望试行一些实验功能或者希望将一些稳定的功能存档,我们可以创造分支。
git以树的形式创造分支,相对于svn以复制整个项目库的形式创造分支,有着非常巨大的性能优势。
分支
当我们创建一个新项目时,git会先创建一个默认分支(main或master)。需要注意默认分支除了是默认的以外没有任何特殊功能。
我们可以使用git checkout -b或者git branch指令创造一个分支。分支在当前的位置开叉。
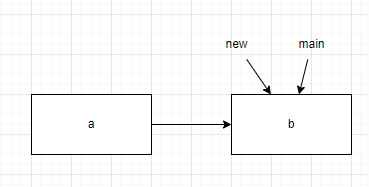
每一个分支都包含a、b这两个提交。每个分支都包含一个指向分支头部(最新的提交)的指针,我已经标记在图上。当我们分别在这两个分支上提交一个数据,提交树则变为:
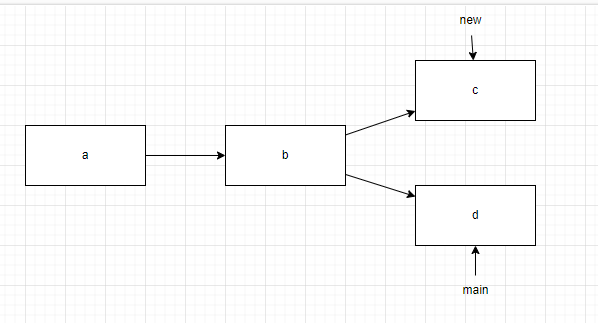
提交树的分叉和提交的内容没有任何关系,即使c与d的内容完全一致,也会分叉为两个。每一个分支包括共有部分(开叉前)和独特部分(开叉后),如果被合并进别的分支的话,每个分支的独特部分对于别的分支是不可见的。
对于提交树来说,任何节点的地位是相同的,我们在树上的任意一点都可以创建新的分支或进行分支操作。
HEAD指针
git仓库默认生成一个指针HEAD,代表了项目库当前的状态。
git比较HEAD节点和项目实际情况,决定add时将什么放入暂存区。当我们切换到任意一个分支时,HEAD指针也会随之转移。因此我们必须暂存或者丢弃当前的改动。(后文会具体讲解,当然现在的工具也支持带入修改到新的目录(当然伴随着巨大的冲突,因为.gitignore也是git管理的))。提交新的改动的,HEAD指针也会随之转移。
如果我们在不新开分支的情况下使用checkout指令回到某个历史节点。此时HEAD指针会指向目标节点,但是处于游离状态,不能提交内容。
下文提到的origin和upsteam分支也有HEAD节点,只代表默认分支的当前状态。无实际用途。
rebase
我们可以rebase指令修改当前分支的HEAD节点位置。请注意这是个非常危险的改动,将会修改提交历史。git rebase 分支会将当前分支的相较于另一个分支的改动全部作为一个新的提交。这个提交的父节点是另一个分支的最新提交。HEAD指针和分支指针也会转移到新的提交上。可见下图,f节点相对于d节点的改动就是e节点相对于b节点的改动。
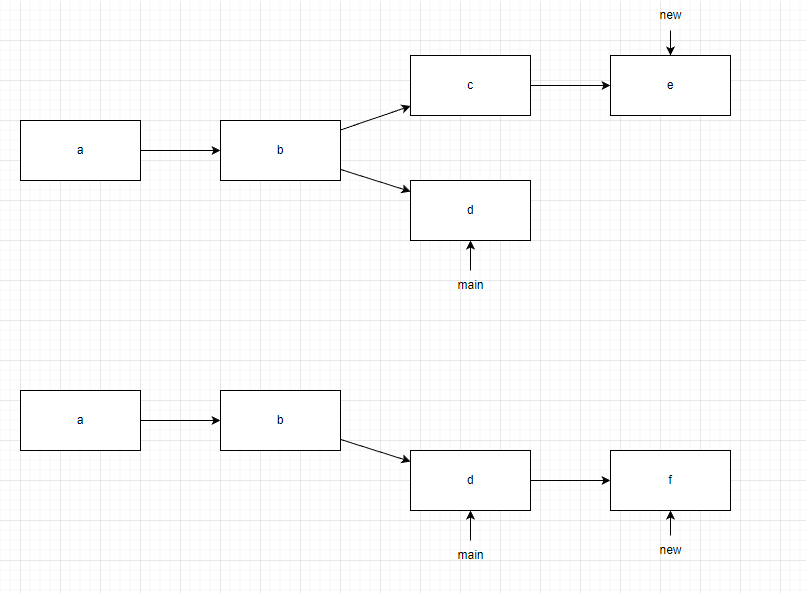
请注意,rebase后git会弹出编辑界面让你选择丢弃的节点的状态,需要根据注释的提醒进行修改。
rebase不仅可以合并到某一个分支,甚至可以指定任意一个提交历史上的节点。git会递归时寻找共同的开叉点并应用差异的更改。例如如果你希望将main分支的前三个提交合并(一般出现在fork的项目,提pr时,需要聚合一下提交避免搞花父项目的log),可以rebaseHEAD-2。git会弹出编辑器让你确认新的提交信息和如何处理丢失的提交,需要选择s(压缩)模式。在GUI中这种操作被称为squash。如果没有特殊必要不要涉及到已经push的提交,可能会导致很多未知问题,并给其他协作者造成大量麻烦。一定要做的话,请明确后果后`force push`(见下文)。
合并
书回上文,如果我们希望main分支接受new的改动后删除没用的new分支,我们可以如下操作。先checkout到main分支然后使用git merge指令合并new分支。此时因为f节点是d节点的子孙节点,所以git只需要将main的指针指向f节点就行。此时HEAD、new、main指向同一个提交。
这种合并被称为快速合并。
如果不是子孙节点,那情况会比较特殊,例如下图在new分支中会多出一个提交节点,内容为从d分支合并。此时new分支包含以下内容:a、b、c、e、f。main分支不受被合并的影响只有a、b、d三个节点。
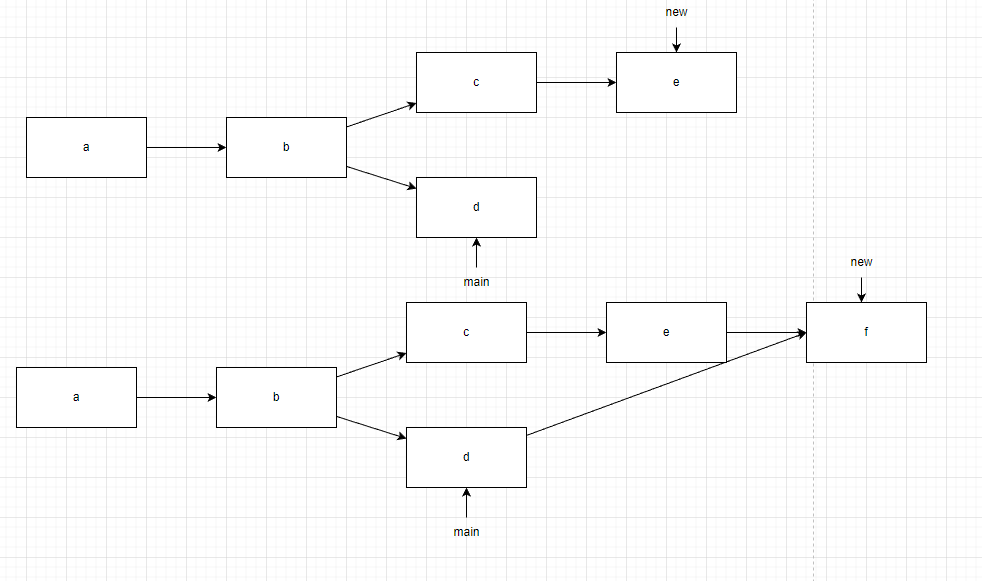
f节点在合并后依然只有一个父节点,仅会在提交信息中提及合并了d节点代表的new分支数据。也就是分支的提交历史永远是链形式而非树。特别是当以下情况:
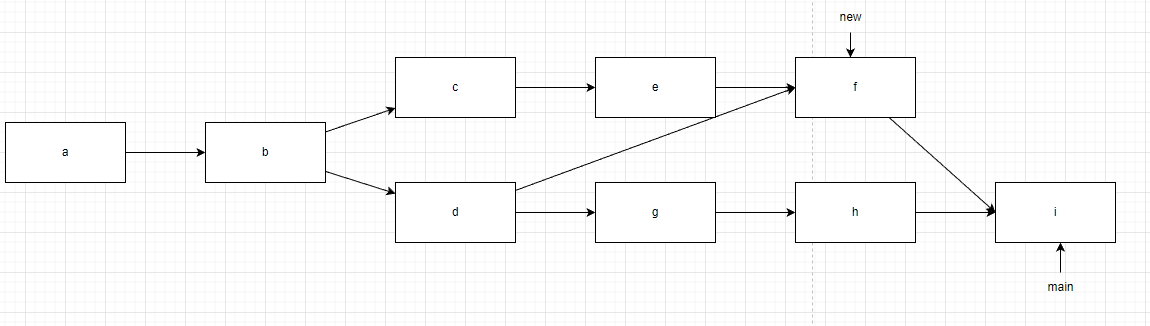
即使几个分支以非常扭曲的形式merge在一起,也不会搞花提交记录。main分支的提交只有a、b、d、h、j、i,f只是被记录在提交内,以供下次合并时确认合并基础点。
git的合并为分支合并,与svn存在本质性区别。svn的合并为选中一个提交,应用到本地更改,通过自动生成的文本作为提交文本的形式标识,需要特别注意。
svn的这种形式的合并在git内应以功能分支的形式出现。当然如果不存在同时维护多个版本的需求时可以简单的推出新版本修复,不合并修复旧版本。
远程分支、fork与PR
以上篇章讲解了单人工作的情况,但是多人协作才是git的主要使用场景。
远程分支
在小团队的通常工作流程里,leader会建一个git服务器,在上面建立一个远程仓库。协作者clone远程仓库,形成一个本地git目录。需要注意本地目录没有什么特殊之处,他也可以被当成一个普通git目录使用。
clone命令会根据远程仓库的分支,在本地检出(checkout)对应的分支。例如远程仓库有一个main分支,本地也会检出一个main分支,同时会检出一个远程分支origin/main,main分支的默认追踪分支(跟踪分支:两个分支一一对应)为origin/main。跟踪分支又叫做上游分支,请注意fork时会生成一个远程分支upstream/main,这个和上游分支有本质性区别,需要注意分辨。
这里的origin和main、master一样,没有什么特殊含义,就是单纯的默认名。远程分支包括远程仓库名称和地址。origin下面可能会存在多个分支,具体看检出方法。
可以为分支更改地址,例如将github改为gitlab来提高生产环境的稳定性。
远程分支与本地分支不同,他是虚拟的,不能进行常见的分支操作也不能在远程分支上直接提交。只能通过对应本地分支进行修改再进行推送的形式修改。
当别人提交了一些数据后,可以利用git fetch指令更新远程分支的状态。origin/main会向前推进并创建新的提交节点,请注意HEAD并不会前进。需要我们进行合并后才能。
接下来讨论我们希望更新远程仓库的方法。
假设我们对main分支提交b、c后,提交树的状态变更为以下。
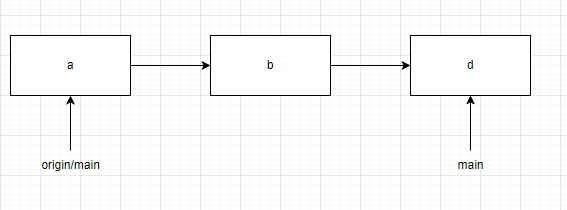
我们可以执行push指令将本地的改动推送到远程。此时git会先向git服务器询问能否执行push,如果服务器确认接受push后(远程main分支可以快速合并到d且当前没有正在进行的其他push),会执行以下流程
git服务器接受b、d两个提交
将服务器的对应分支指针指向d(综合前一步看就是合并)
如果为默认分支会移动HEAD
返回git客户端执行成功
客户端收到成功后,会将本地的origin/main指向d。
但是,如果有人在b之前提交了一个a1操作,push会被拒绝。此时我们需要执行pull操作,这个操作的核心是一个fetch和一个merge。a1会被拉取到本地并会被合并到d。这个操作可能会触发合并冲突。在我们解决合并冲突后,提交树如下。
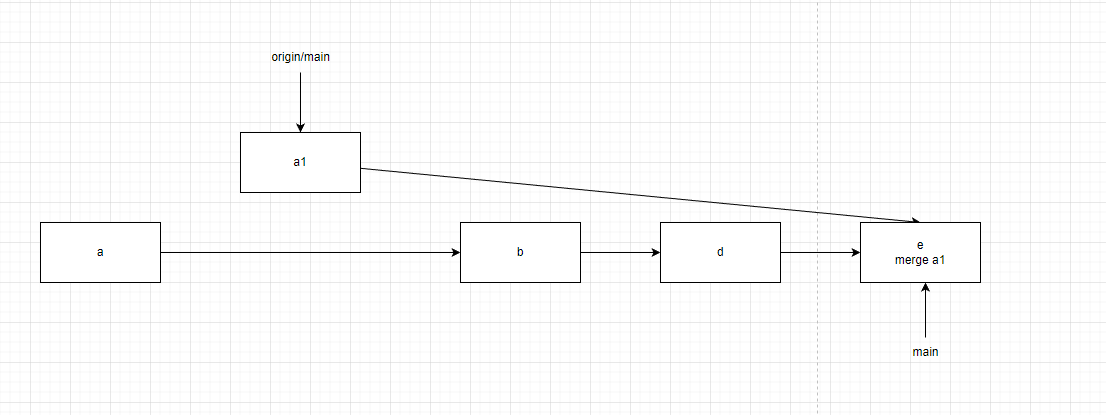
此时我们再执行push操作就能将b、e的改动推到服务器上,此时服务器上的状态为:
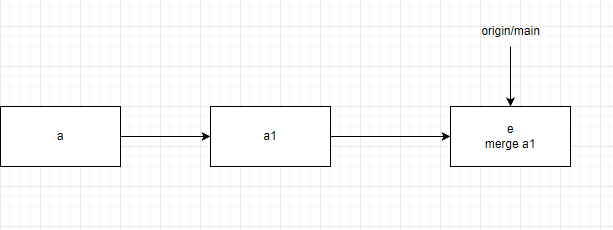
本地状态为:
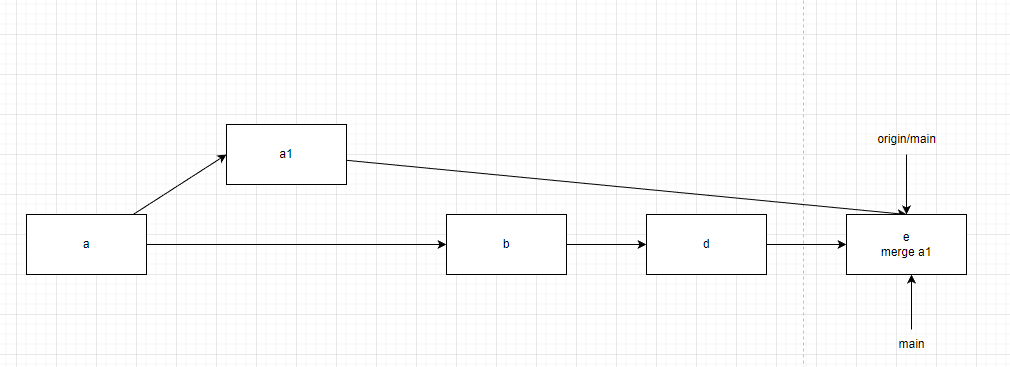
在此过程中如果继续发生push冲突需要继续进行同样的操作。
有些人觉得这样的方式太令人困惑了,那我们可以使用git pull --rebase。即不以merge的方式合并main和origin/main,而是以rebase的方式。那本地的提交树会变成以下情况。
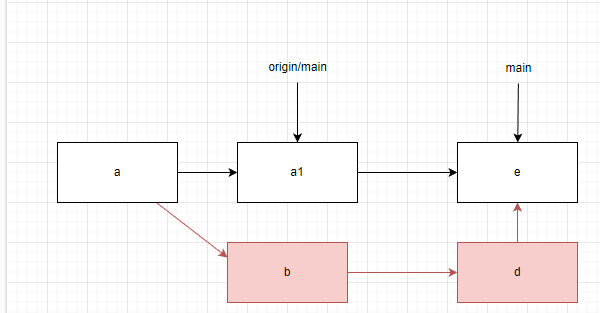
b、d提交被抛弃了。然后执行push就可以快速合并到e。
一般情况下我们不会在本地的main分支进行工作,而会在本地增加一个分支dev,push前rebase到main分支,这样可以大大减少冲突,且可以让提交历史更精简,更聚焦。
如果本地存在未提交的代码,在pull时因为HEAD发生了变动,项目代码也可能会发生冲突,需要解决后才能继续工作。
假如我们在main分支执行了rabase操作,可能会出现push失败的特殊情况。
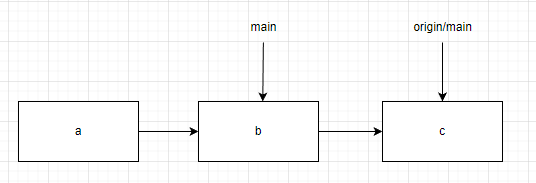
例如在上图这种情况c节点已经在本地被抛弃了,那我们需要再push时加上--force参数,强制更新远程的提交树为本地的副本。在这种情况下git服务器将不会进行历史校验。
如果不清楚--froce可能导致的后果,且不是管理人员,不应该使用--froce。
权限
git服务器可以为clone、pull、push、--force等设定单独的权限。我们需要进行登录认证,或者上传token等形式进行鉴权。因为现在都是一键配置的,所以在此不做赘述。
fork与pr
在github中,开发者希望自己的开源库不会被恶意篡改或者收到大量冗余提交,因此协作者需要fork一份到自己的名下。请注意,被复制后的是独立的远程仓库,与原仓库在git语法下完全隔离。
fork后的仓库会在本地形成一个远程分支:upstream/main,请注意这个和上游分支(追踪分支)没有任何关系。可以对这个分支执行pull,但是一般不能push(如果具备权限也可以推,那本质上换一下origin的地址,就和clone项目直接开发没有关系了,请不要这样做)
当我们在远程分支提交了足够的提交后,我们可以选择将这些提交同步进源仓库。我们需要在github点击pull request,这个行为类似于本地向origin分支push数据。如果开发者同意可以将我们的origin/master分支(举个例子)pull进他的origin/master分支。与pull不同的是,一般情况下源仓库的管理者只接受能快速合并的pull request,我们需要先在本地fetch upstream/main,获取他的修改,解决可能存在的冲突。
规范
尽量在提交前执行`pull`,这样可以执行快速合并,避免产生过多合并节点。合并节点的名字是自动生成的,很容易混淆历史。
尽量使用`rebase`来压缩本地提交。然后使用`ammed`更改提交文本再提交,这样子不管之前是如何执行提交合并,本地都只剩下合并和功能改动,`push`也不会产生多余的合并节点。
工具都在我们手中,可以排列组合形成最优解。当然,如果作为协作者,最好的方法还是研读管理者的文档。
请注意如果`rebase`了未合并的远程分支上的提交,可能会导致出现多个提交和合并,需要手动进行压缩。
标签、版本、issue、discussion与milestone
标签与版本
我们可以为提交打上版本号来标识特殊的提交。例如以下工作流:
协作者
fork组织的仓库,提交代码到自己的dev,提PR进组织的dev,审核者负责审代码确认合并进dev。能够加版本号了,就向组织的main提交,需要发布就从main拉一个分支用于发布。
我们可以使用git tag命令为提交打上版本号,用来确认阶段性的提交。格式一般为v0.1、v0.2、v1.1,如果是测试版本就在其后+b。
在github中,我们可以为版本号生成release版本或者创建release版本顺便生成版本号。可以写一些bug fix或者add feature文本来指出这个版本的修改。如果出现api不兼容级别的改动,或者完全重做逻辑,则需要为大版本号+1(当然也可以和chrome一样乱加)。同时兼容两个版本的情况下建议从main分支拉出单独的发布分支,每个版本同时拥有自己的版本号。具体可以参考一些git工作流相关的书籍。
issue、discussion、project与milestone
协作者可通过提交issue来报告bug或提出功能需求。在相应的issue下,我们可以展开有关问题的讨论。管理者有权将这些issue整理归类到一个宏伟的milestone下。
建立discussion可促进管理者和协作者进行广泛的讨论和闲聊。此外,通过project功能,我们可以使用看板进行更有效的项目管理。
以下提供一种工作流程:
1.0版本的规划阶段,管理者建立一个discussion讨论1.0有哪些功能,需要修复哪些bug。
在截止时间时后,管理者建立1.0milestone,并为相应的功能添加issue。
协作者不停完成提交并提pr,将pr关联到对应的issue,合并进dev分支。
如果过程中出现优先度高的issue可以加入1.0版本计划
完成所有milestone后进行集成测试
经过内部测试定版后,打上tag1.0b,并拉取dev到master,发布release1.0b进行外部测试或更新给部分用户进行灰度测试。
稳定后发布release1.0正式版本。
其他
stash
一般要求提交后的版本是可以被编译的,完整的。但是,开发者经常会遇到写代码的过程中,有紧急的需求需要立刻处理,导致我们必须暂存改动来应付别的需求。
我们可以将工作分支中的修改使用git stash指令先保存下来,切换到另一个功能分支完成紧急提交后,再释放出来。
二进制文件
git会在本地存储全量的历史,因此非常不适合存储二进制文件,例如excel表等,建议套一个svn使用。svn和git都是非常绿色的,状态全都存储在.git\svn隐藏文件夹下,没有外部状态。因此可以安心使用,不用担心冲突。
也可以考虑一些中心化方案。
不提交的合并
有时我们不需要合并整一个分支,但是我们希望合并的部分并不是以功能分支的形式被合并的,我们可以使用pickup指令将这部分的提交带到当前分支。
建议以这样的形式应用提交再用rebase进行组合,不要使用svn式的方案(因为我不想用,我都忘记指令了)。
子模块
有时,我们需要使用git submodule add嵌套部署git仓库。
比如我们需要一些git管理的本地依赖。特别常见于一些没有本地依赖管理的包,或者包管理延迟比较高的情况。比如github+golang,几分钟都不一定拉得到最新的,就需要本地搞一个子模块并用replace或者gowork指向。
放在项目下面作为子模块的好处就是比较方便管理,不容易混淆。例如a、b项目都在code文件夹下,a项目又依赖于某个特性版本或者需要本地实时改实时上传的b项目,就可以放一个b在a下面。
clone 父项目后,子项目也会被clone下来,此时千万注意此时子项目的HEAD指向main但是是分离状态的。在此状态下可以提交,但是不能push,必须切换分支后提交,不然代码会丢失(猜猜我是怎么发现的TAT)。
如果在子项目有提交,需要在父项目也提交,避免另一个用户更新不到。此时如果另一个用户有本地的改动,会处于分离状态,需要切换到main,但是代码不会丢。
如果子项目没有提交,父目录直接提交了子模块原信息,远端是拉不到子模块的。需要提交子模块后,执行 `git submodule update --init --recursive`
后文
虽然在正文中讲起来好像非常复杂,但是我们很多时候并不需要执行非常复杂的命令行程序,只需要在UI上点点点。研究不明白就在本地分支上多试试就行。
不过虽然强大的UI工具可以降低大量的工作量,但是世界上并没有银弹,逻辑上的复杂性往往是守恒的,只不过从命令行指令的排序转移到UI上。所以大家了解git相对底层的原理还是很有必要的。
本文跳过了很多细节,因为我们并非git开发者,对于过度深入的底层原理并没有理解的必要性,因为git提供的接口都是封装好的最小化黑盒。
有些古早的协作方案也被我跳过了,以前没有gitlab、github这种账号式的继承环境因此搞了一套得吃复杂的本地鉴权和邮件协作方式,现在已经没有这个必要了。用户名、邮箱、认证、SSH秘钥也可以通过账号登录的形式一站式搞定了。话说起来他们作为互相耦合的一部分,必然存在一站式的部署方式。
有些零零碎碎的就不说了,包括revert,因为是独立的,不在系统里面。
此外需要感谢drawio,本文的示意图终于不是ppt画的或者截图软件拼出来的。当然如果drawio可以选中时按键自动切换到节点的输入模式这个功能,假如更好的输入法支持就好了,目前会吃掉第一个字母。
顺便在本文之末推荐下根据正则批量加``的语句,就不用一个个手动替换博客中的所有术语了。
(?<!`)(gitlab)(?!`)
替换为
`$1`说起来博客又变成了半年更了:)